[Tuto] Boost ton ML : XGBoost facile & efficace avec R !
September 2, 2018
datascience data machinelearning R tools tutorialCet article requiert d’avoir quelques notions de base du langage R. Il s’adresse à tout professionnel ou amateur de la modélisation (pardon, du Machine Learning ;-)). L’objectif est d’acquérir le savoir-faire nécessaire pour entraîner et évaluer les modèles XGBoost avec R. Mon choix s’est porté sur XGBoost car en plus d’être très performant pour une large palette de problématiques, il a d’autres caractéristiques qui le rendent assez indispensable à avoir dans sa boîte à outils. Nous nous attacherons dans ce qui suit à écarter toutes les difficultés & complications de manière claire et pragmatique.
A l’issue de ce tuto, tu sauras donc :
- Ce qu’est XGBoost
- Comment préparer tes données
- Comment ajuster et optimiser ton modèle avec XGBoost
- Comment évaluer, visualiser et explorer ton modèle

Régression Linéaire
I. XGBoost, pourquoi on en parle autant ?
Parce qu’il est vraiment BON et aussi un peu beaucoup grâce à Kaggle.
En effet, son utilisation est assez systématique dans les solutions gagnantes de Challenges Kaggle portant sur des données structurées. XGBoost a une excellente précision et s’adapte bien à tous types de données et de problématiques, ce qui en fait l’algo idéal quand la performance et la rapidité priment.
Nous verrons dans la suite ce qui le rend si performant.

X G B O O S T (Sans exagération aucune.)
II. XGBoost, qu’est ce que c’est & comment ça marche ?
XGBoost (eXtreme Gradient Boosting) est une implémentation open source optimisée et parallélisée du Gradient Boosting, créée par Tianqi Chen, Doctorant à l’Université de Washington. XGBoost utilise des arbres de décision (comme Random Forest) pour résoudre des problèmes de classification (binaire & multiclasse), de classement (ranking) et de régression. Nous sommes donc dans le domaine de l’apprentissage supervisé.
XGBoost fait partie de la famille des méthodes ensembliste. La différence par rapport aux méthodes classiques, c’est qu’au lieu d’entraîner le meilleur modèle possible sur les données, on va en entraîner des milliers sur des sous-parties diverses du jeu de données d’apprentissage, puis les faire voter pour prendre notre décision.
En effet, avant de prendre une décision “difficile”, n’est-il pas d’usage de demander leur avis à plusieurs personnes de son entourage ? Ainsi, on recueille plusieurs points de vue sur le problème, plusieurs manières de l’appréhender, et on a donc plus d’informations pour prendre la décision finale.
Maintenant, XGBoost comprend quelques subtilités qui le rendent véritablement supérieur. Parmi elles, le procédé de Boosting. Le principe du boosting est d’améliorer la qualité de prédiction d’un modèle médiocre (weak learner) en donnant de plus en plus de poids aux valeurs difficiles à prédire au cours de l’apprentissage. Ainsi, on oblige le modèle à s’améliorer.
Cependant comme on dit, “With great power comes great responsibility”. XGBoost a un peu plus de paramètres à tuner que la moyenne, mais nous verrons qu’il n’y a là rien de bien compliqué quand les choses sont clairement définies. De plus, nous verrons que le package caret apporte une assistance non négligeable dans la mise en oeuvre. Je vais aussi m’efforcer de donner un paramétrage générique et réutilisable pour une diversité de problématiques.
III. XGBoost, pourquoi c’est génial ?
- 1. Parallèlisation: par défaut, l’algorithme utilise tous les cœurs du microprocesseur de la machine, d’où un sérieux gain de temps.
- 2. Régularisation: XGBoost comprend une régularisation, ce qui permet d’éviter le surajustement (over-fitting). Ainsi, on a plus de chances d’obtenir un modèle qui performe bien sur échantillon d’apprentissage, sur échantillon de test, et aussi sur de nouvelles données. On dit qu’il est généralisable.
- 3. Non linéarité: Etant basé sur des arbres de décision, XGBoost capture tous types de liaisons entre données, y compris non linéaires.
- 4.Validation croisée: intégrée dans l’algorithme, il n’y a pas besoin de la programmer par ailleurs.
- 5. Données manquantes: gérées nativement par l’algorithme. Il est capable de capturer et comprendre leur structure, dans le cas où elles ne sont pas dues au pur hasard.
- 6. Flexibilité: possibilité de faire de la régression, de la classification et du classement (ranking). De plus, il est possible de définir soi-même une fonction objectif à optimiser lors de l’entraînement du modèle. Très utile en classification quand on veut par exemple donner plus de poids aux faux négatifs qu’aux faux positifs ou l’inverse. Cette fonctionnalité est très utile dans la détection de la fraude et dans le dépistage de maladies graves.
- 7. Disponibilité & scalabilité: XGBoost est utilisable avec la majorité des plateformes (Windows, Linux, macOS) et des langages (C++, Java, Python, Julia). Il peut aussi tourner de manière distribuée sur Apache Hadoop, Spark, et Flink, ce qui ouvre la porte au traitement de données véritablement massives (allez, on va dire un gros mot : “big data”).
- 8. Save & Reload: Entraîner & sauvegarder son modèle & sa matrice de données avec Python. Les recharger (soi-même ou quelqu’un d’autre) plus tard avec R pour usage de prédiction immédiat. What Else ?
- 9. Elagage des arbres (tree-pruning): Consiste à supprimer les branches (parties terminales) d’arbres de décision peu utiles pour la prédiction. Ainsi, on simplifie le modèle final, et on gagne en performances prédictives (généralisation).
IV. XGBoost en pratique
1. Les données
library(tidyverse)
library(xgboost)
library(caret)
library(readxl)Le jeu de données choisi comprend 9568 lignes de données collectées sur une centrale électrique au gaz sur une période de 6 ans (2006 à 2011), en fonctionnement à pleine puissance.
Il est à télecharger ici
# Import & création de noms de colonnes plus parlants :
df <- read_excel("Folds5x2_pp.xlsx")
colnames(df) <- c("Temp", "VEchap", "PressAtm", "Humid", "ProdElec")Voici un aperçu des données :
DT::datatable(head(df, n = 50))Les variables sont des moyennes horaires de mesures faites grâce à des capteurs dans la centrale. Chaque ligne correspond à une heure de mesure. Elles sont brutes, ni centrées ni réduites :
Prédicteurs (X) :
Temp= Température ambiante (en °C)VEchap= Vide d’échappement (en cmHg)PressAtm= Pression atmosphérique ambiante (en millibars)Humid= Humidité relative (en %)
Variable réponse à prédire (y) :
ProdElec= Production électrique (en MWatt)
2. Un peu d’exploration
Nous sommes en présence d’un jeu de données 100% quantitatif. Commençons donc par regarder rapidement les corrélations entre variables.
Pour rappel, le coefficient de corrélation de Pearson \(\in [-1,1]\) et mesure l’intensité de la liaison qui peut exister entre deux variables.
“La liaison peut être négative ou positive. Il est égal à 1 dans le cas où l’une des variables est une fonction affine croissante de l’autre variable, à -1 dans le cas où une variable est une fonction affine et décroissante. Les valeurs intermédiaires renseignent sur le degré de dépendance linéaire entre les deux variables. Plus le coefficient est proche des valeurs extrêmes -1 et 1, plus la corrélation linéaire entre les variables est forte”" (Source)
La direction de l’ellipse (haut ou bas) renseigne sur le signe de la corrélation, la couleur sur son intensité :
library(corrplot)
corrplot(cor(df), method = "ellipse")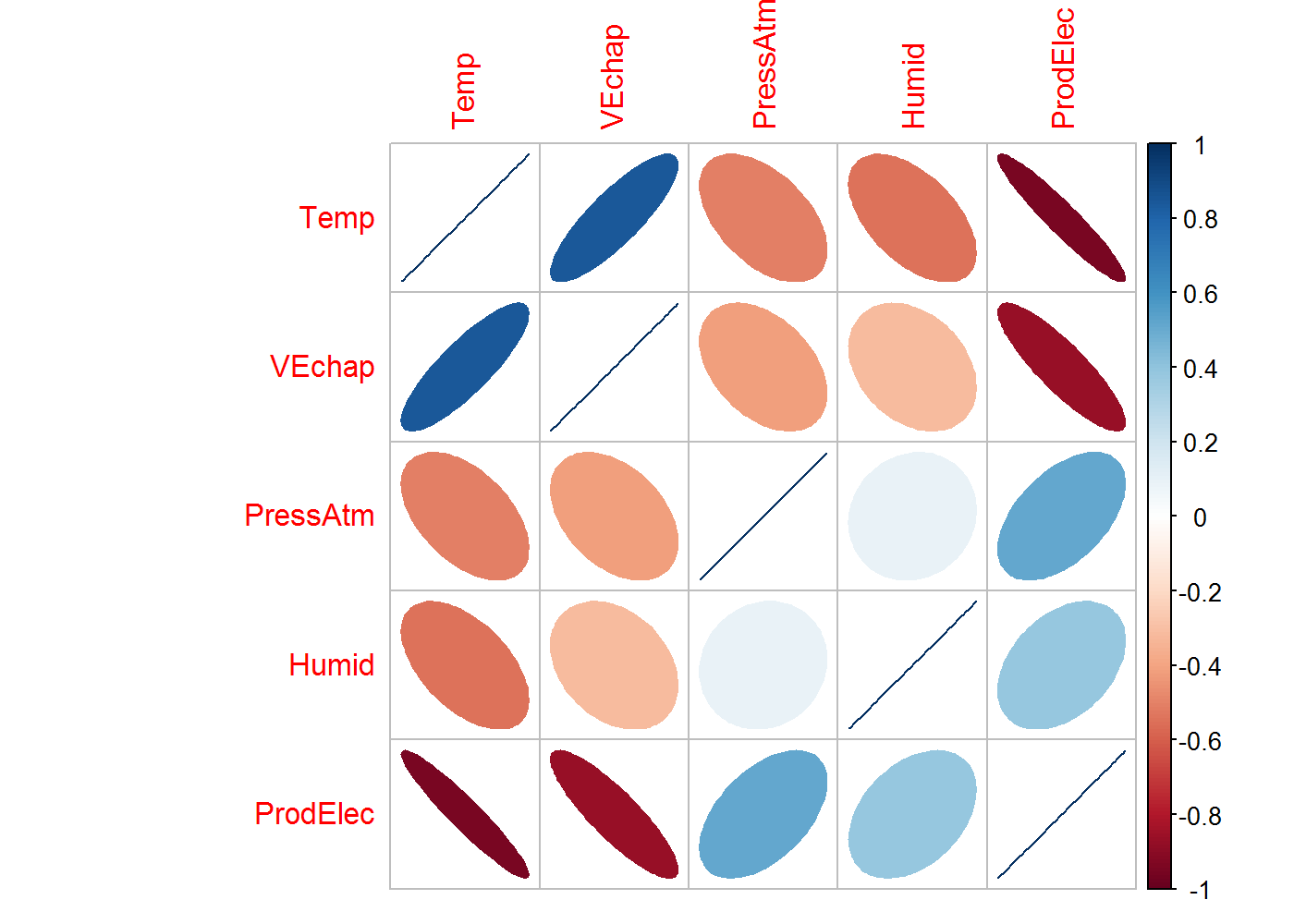
En représentant les nuages de points des variables deux à deux :
library(GGally)
ggpairs(df)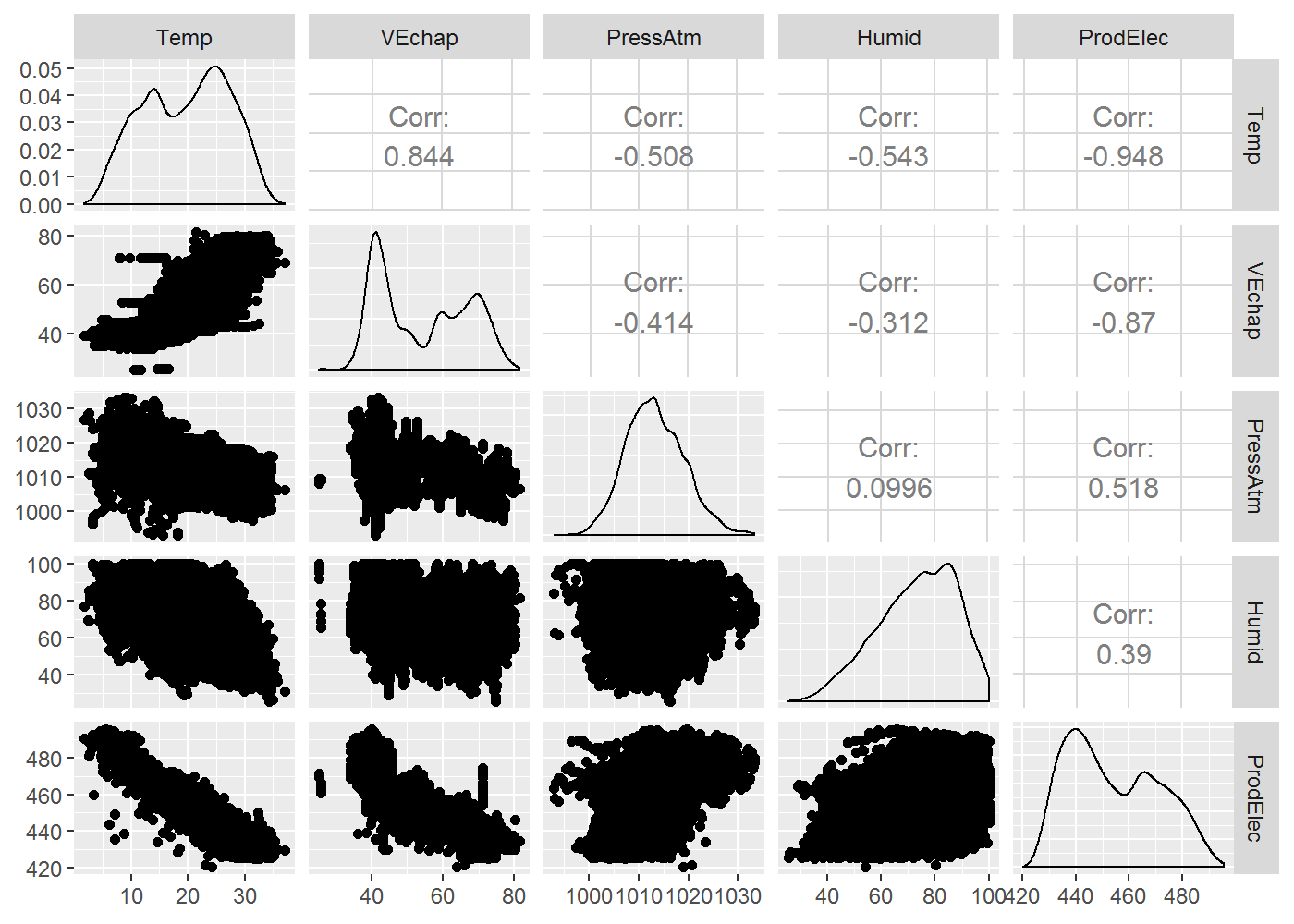
Logiquement, donc, nous devrions voir que ProdEle décroit en fonction de la Temp :
ggplot(data = df, aes(x = Temp, y = ProdElec)) + geom_point() + geom_smooth(method = "lm")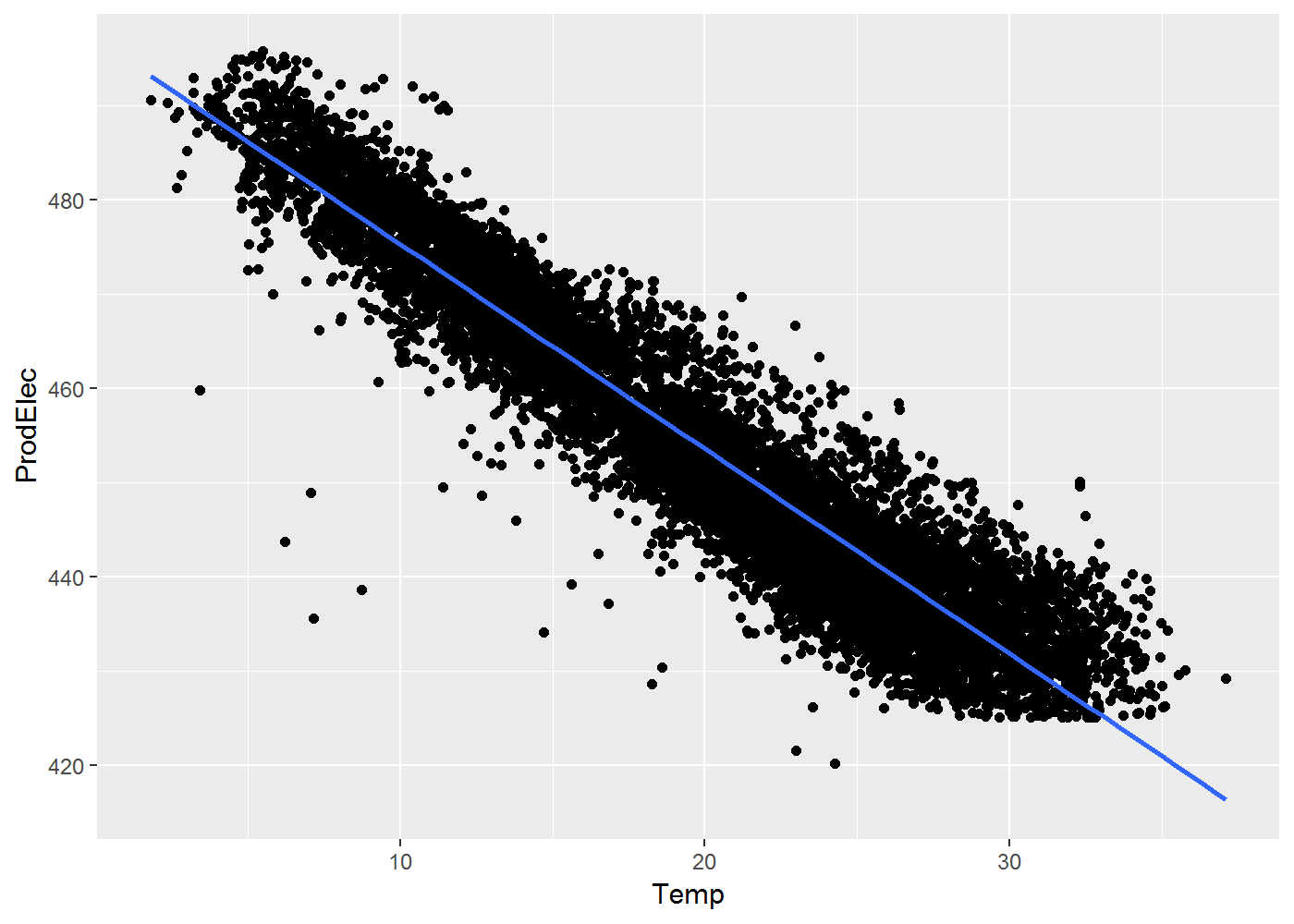
Et percevoir une relation croissante entre PressATm et ProdElec :
ggplot(data = df, aes(x = PressAtm, y = ProdElec)) + geom_point() + geom_smooth(method = "lm")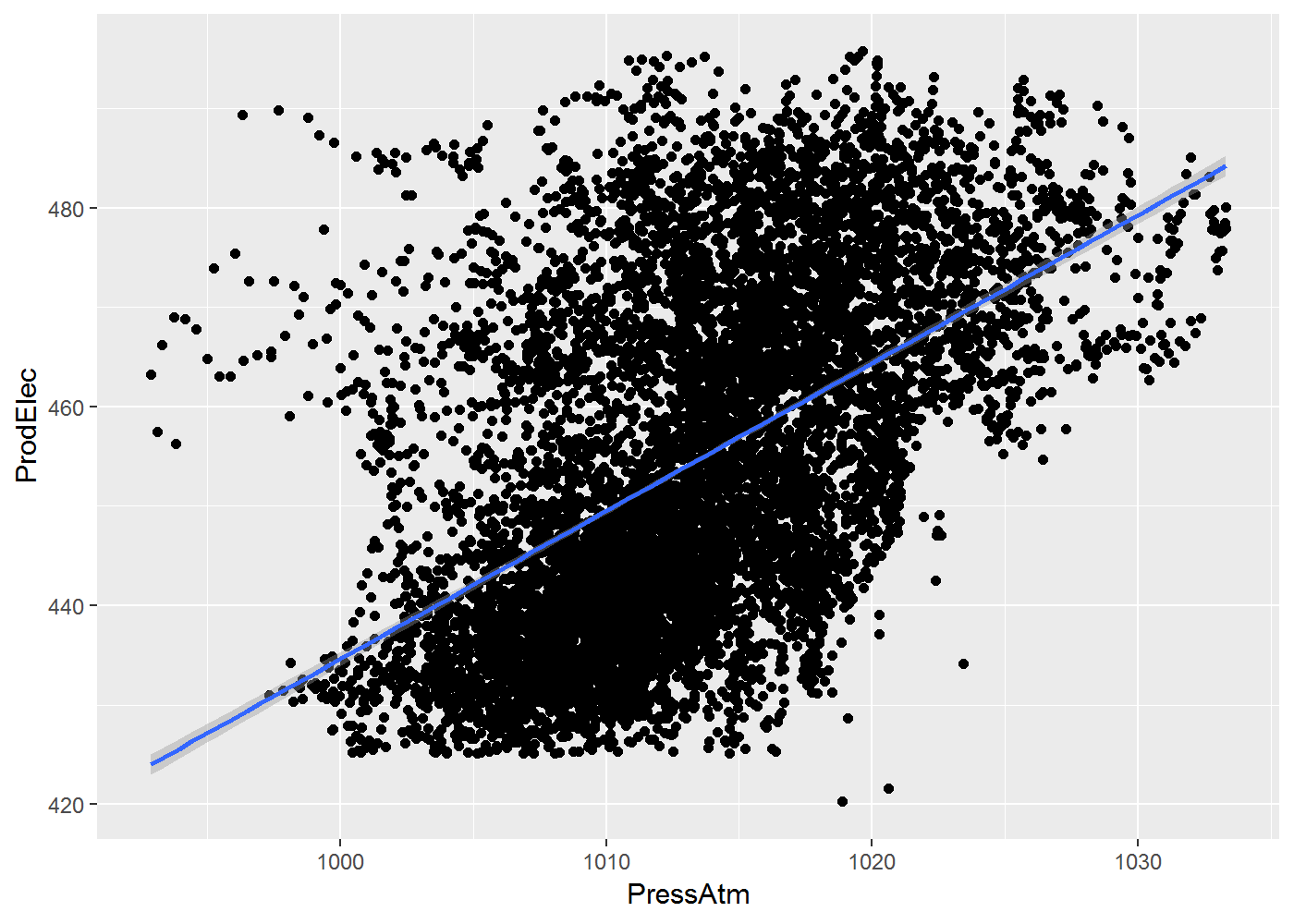
3. Maintenant, le modèle !
Commençons par diviser le jeu de données en un échantillon de d’entraînement appelé training et un second de test appelé testing:
set.seed(1337) # Pour la 'reproductibilité'
inTrain <- createDataPartition(y = df$ProdElec, p = 0.85, list = FALSE) # 85% des données dans le train, et le rest dans le test
training <- df[inTrain, ]
testing <- df[-inTrain, ]On sépare ensuite le vecteur réponse y de la matrice X des prédicteurs pour les deux échantillons.
Dans le cas où l’on a des variables qualitatives dans les données, il faut les encoder en variables binaires (one-hot encoding/dummy) Les matrices doivent obligatoirement être converties au format xgb.DMatrix :
X_train = xgb.DMatrix(as.matrix(training %>% select(-ProdElec)))
y_train = training$ProdElec
X_test = xgb.DMatrix(as.matrix(testing %>% select(-ProdElec)))
y_test = testing$ProdElecPassons aux choses sérieuses !

Nous allons utiliser le super package caret (si vous êtes utilisateur R & que vous ne le connaissez pas, courez ICI !).
On va donc commencer par définir un objet trainControl, qui permet de contrôler la manière dont se fait l’entraînement du modèle, assuré par la fonction train().
Ici, nous choisissons une validation croisée (method = ‘cv’) à 5 folds (number = 5). On choisit également d’autoriser la parallélisation des calculs (allowParallel = TRUE), de réduire la verbosité (verboseIter = FALSE).
xgb_trcontrol = trainControl(method = "cv", number = 5, allowParallel = TRUE,
verboseIter = FALSE, returnData = FALSE)On définit ensuite une grille de paramètres du modèle XGBoost appelée xgbGrid.
xgbGrid <- expand.grid(nrounds = c(100,200),
max_depth = c(3, 5, 10, 15, 20),
colsample_bytree = seq(0.5, 0.9, length.out = 5),
## valeurs par défaut :
eta = 0.1,
gamma=0,
min_child_weight = 1,
subsample = 1
)caret testera chaque combinaisons de ces paramètres dans un modèle distinct. Je me risque ici à faire une description simplifiée de quelques paramètres essentiels:
- nrounds: nombre d’itérations de boosting à effectuer. Plus il est grand, et plus c’est lent
- max_depth: profondeur d’arbre maximale. Risque d’over-fit si trop grand, et d’under-fit si trop petit
- colsample_bytree: pourcentage des colonnes pris pour construire un arbre (rappelle-toi, un arbre est construit avec un sous-ensemble des données: lignes et colonnes)
- eta: ou learning rate, ce paramètre contrôle la vitesse à laquelle on convergence lors de la descente du gradient fonctionnelle (par défaut = 0.3)
- gamma: diminution minimale de la valeur de la loss (fonction objectif) pour prendre la décision de partitionner une feuille
Vous trouverez ici une explication approfondie et exhaustive.
On a ici 40 combinaisons de paramètres possibles, donc 40 modèles à entraîner. Voici une dizaine d’exemples de combinaisons de paramètres :
Allons-y pour l’entraînement :
set.seed(0)
xgb_model = train(X_train, y_train, trControl = xgb_trcontrol, tuneGrid = xgbGrid,
method = "xgbTree")Si c’est un peu lent, c’est normal. Souvenez-vous qu’on entraîne un grand nombre de modèles avec validation croisée.
4. Place à l’évaluation du modèle
Voici les paramètres du modèle optimal trouvé par caret :
xgb_model$bestTune## nrounds max_depth eta gamma colsample_bytree min_child_weight subsample
## 28 200 10 0.1 0 0.8 1 1Et les metrics de performance :
predicted = predict(xgb_model, X_test)
residuals = y_test - predicted
RMSE = sqrt(mean(residuals^2))
y_test_mean = mean(y_test)
tss = sum((y_test - y_test_mean)^2)
rss = sum(residuals^2)
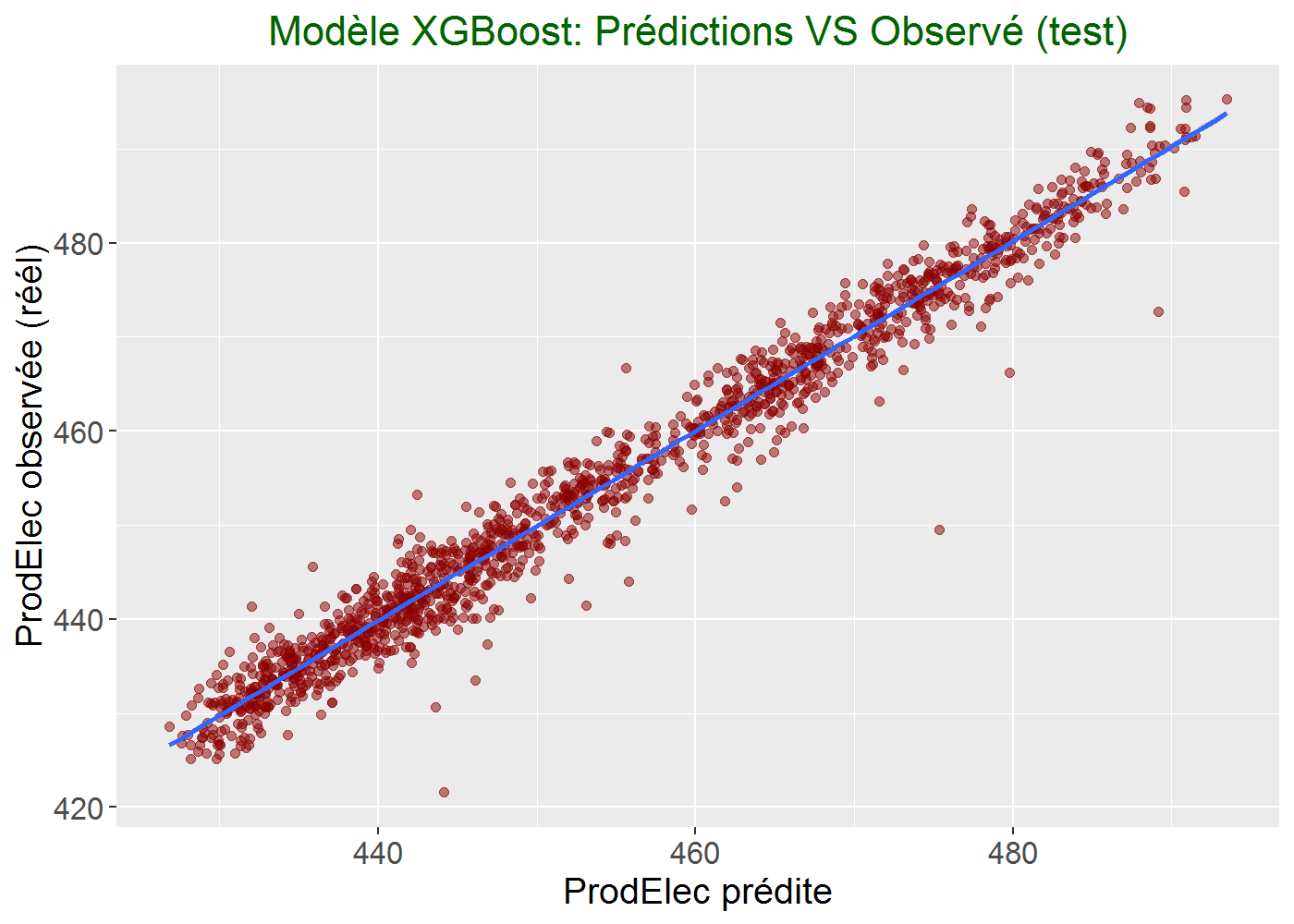
rsq = 1 - (rss/tss)l’Erreur-type de prédiction des valeurs de ProdElec (RMSE) sur échantillont de test est de 2.87, sachant que ProdElec prend des valeurs entre 420.26 et 495.76
Le coefficient de détermination (R²) de test est de 0.972
Pas mal non ?
Graphiquement, lorsqu’on représente ce que prédit le modèle en fonction de l’observé :
V. Conclusions
On est donc plutôt bons. Voir même très très bons ! :-)
Nous avons pris ici un exemple plutôt simple : 4 prédicteurs, moins de 10 000 lignes, des variables quantitatives uniquement, pas de données manquantes, et des données avec une structure bien présente (corrélations entre variables) et assez facile à déceler graphiquement. J’ai fait ce choix pour concentrer l’attention sur la méthode plutôt que sur les données et leur compréhension. Ce problème aurait pu être résolu assez efficacement et plus rapidement avec un modèle plus simple (régression linéaire, par exemple).
Il faut savoir que XGBoost brille véritablement en conditions … eXtrêmes, ou plutôt dans les conditions normales que l’on rencontre dans la vraie vie : données massives, mix de variables quantitatives et qualitatives (one-hot encodées), données manquantes par-ci par-là, liaisons non-linéaires complexes, etc.
Petite précaution à prendre cependant, XGBoost n’est pas le meilleur choix pour les jeux de données comptant plus de colonnes que de lignes, et pour les données 100% qualitatives. Pour d’autres applications telles que la reconnaissance d’image, la Computer Vision, le traitement du langage naturel, XGBoost n’est pas un choix judicieux non plus.
Voilà ! Les commmentaires/questions/critiques/corrections sont les bienvenus.
Merci = D

Sinon pour aller plus loin :