L’Usine ML, une application web de Machine Learning automatique écrite en R et Shiny
July 23, 2018
datascience R shinyDepuis un simple navigateur web, en quelques clics et zéro code, menez un projet de Machine Learning (modélisation prédictive, classification ou régression) sur des données en 3 étapes simples :
D’abord, les données ! - Choix du jeu de données (5 datasets démo dispo pour le moment), de la variable à prédire et des variables explicatives à utiliser pour la modélisation. On choisit également la taille du jeu de test (en % du total).
Entraînement & choix du modèle - En un clic, l’app entraîne et optimise automatiquement jusqu’à 56 modèles différents (SVMLinéaire, Neural Net, Random Forest, kNN, SVMPoly, Naive Bayes) et choisit le meilleur en termes de performance. Plusieurs métriques et graphiques sont affichés et permettent de comparer les modèles.
Performance de modèle - Caractéristiques du meilleur modèle.
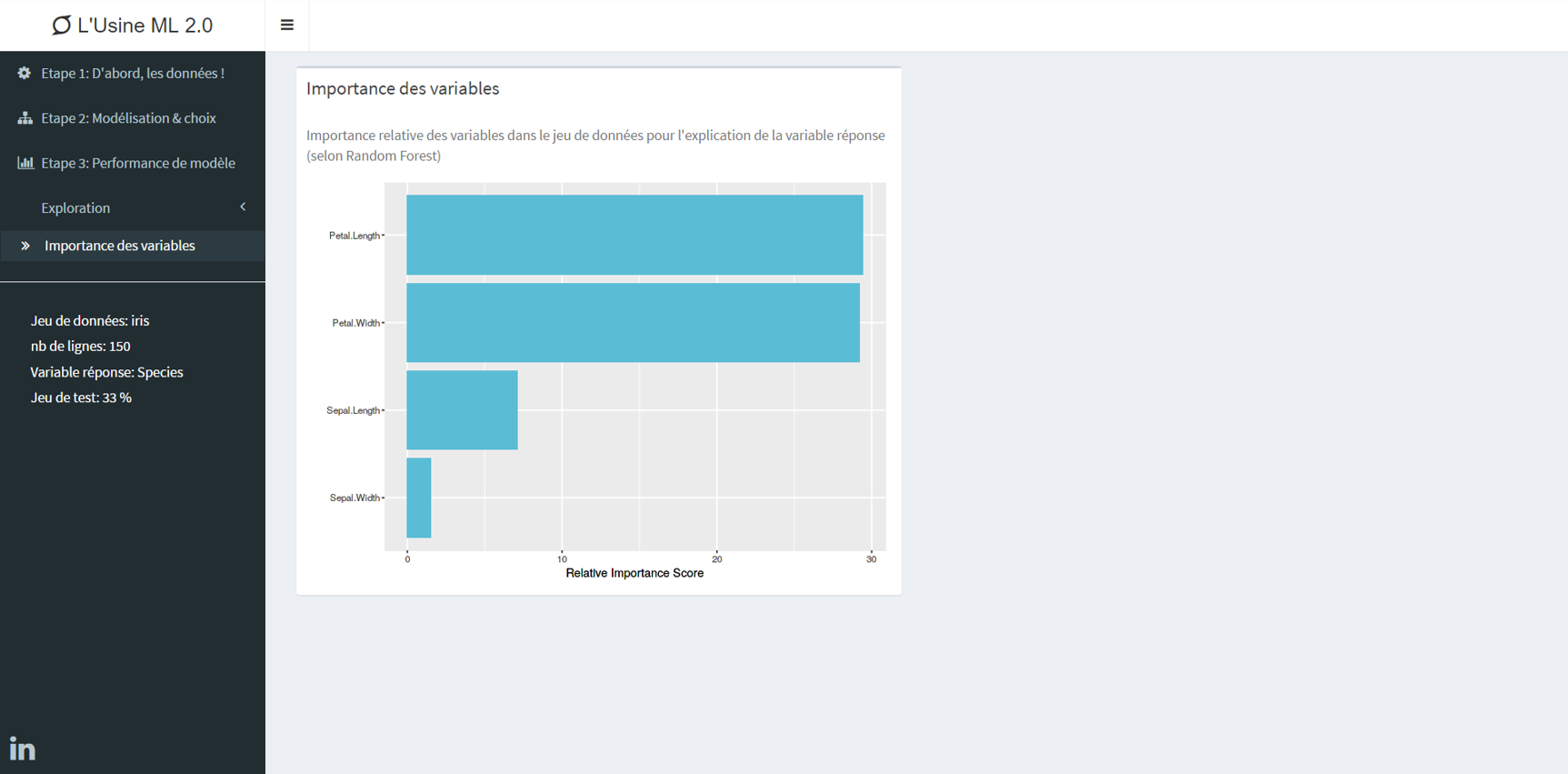
En supplément : un onglet permettant de savoir quelles variables ont la plus grande importance dans la prédiction de la variable à expliquer.
Exemple : sur le jeu de données classique iris (modèle de prédiction de l’espèce à laquelle appartiennent des fleurs d’iris sur la base de 4 mesures de pétales et de sépales), on obtient une précision de 97.9% sur échantillon de test avec un réseau de neurones.
Tout ça en quelques clics et 2min top chrono ! ;-)
Le lien est par ici !
Voici ce que ça donne en images :
Première étape : choix des données, de ce que l’on veut prévoir, en fonction de quoi. Visualisation du jeu de données, choix de la taille de l’échantillon de test.

Etape 2 : le cœur de l’application, permet d’entraîner une large palette de modèles et de sélectionner le meilleur parmi eux en toute transparence.

Métriques des modèles
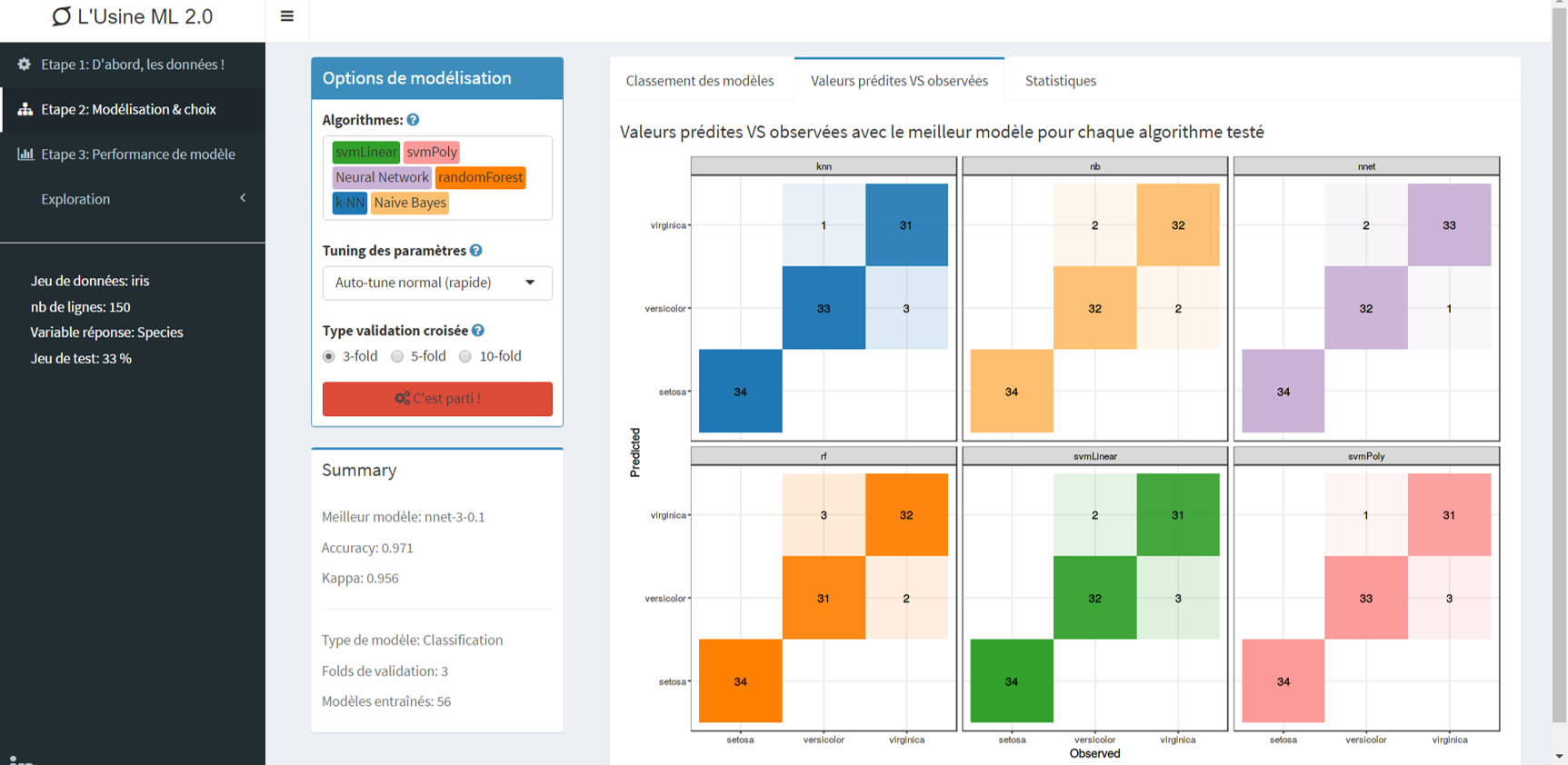
Caractéristiques du modèle gagnant !

Importance des variables : quelles données nous aident le plus à prédire ?
Ceci est plus une “démo” de ce que l’on peut faire avec l’outil R et Shiny qu’une application destinée à un usage intensif par des centaines de personnes at scale. Moyennant un peu d’optimisation cependant, ce petit outil évolutif peut très bien trouver sa place dans la toolbox d’une équipe data comme moyen de gagner du temps sur des problèmes classiques.
Si ce genre d’outil vous intéresse, n’hésitez pas à consulter la doc de Shiny, qui est ultra bien faite et parfaitement abordable avec une pratique novice de R grâce aux vidéos. A noter qu’il n’y a absolument pas besoin de maîtriser les langages front-end (HTML, CSS, JavaScript) pour développer ce genre d’application, R se charge de cette partie, et génère des pages web toutes faites, étonamment bien construites ! L’outil commence à être mature et est très stable, et s’enrichit de librairies haut niveau permettant d’aller plus vite dans la fabrication d’apps Shiny (cf. Shinydashboard).
Un point intéressant à garder en tête est qu’une application Shiny contient un serveur R. C’est donc une vrai application, dans le sens où elle est capable de requêter toutes sortes de services, de bases de données & d’API. Elle est capable, en temps réél de faire des calculs, de générer des graphiques dynamiques, de lire et d’écrire.
Pour construire la même application, une base de code largement aboutie est disponible gratuitement en ligne sur Github sous le projet machLearn de David Stephens.
Un projet identique mais un peu plus musclé est trouvable ici. Il présente la particularité d’utiliser l’excellent H2O pour la partie Machine Learning et Plotly pour les graphiques, interactifs et d’une qualité exceptionnelle. Pour le moment, seuls les modèles de classification sont disponibles (Deep Learning, Random Forest, Gradient Boosting Machine, Modèle Linéaire Généralisé).